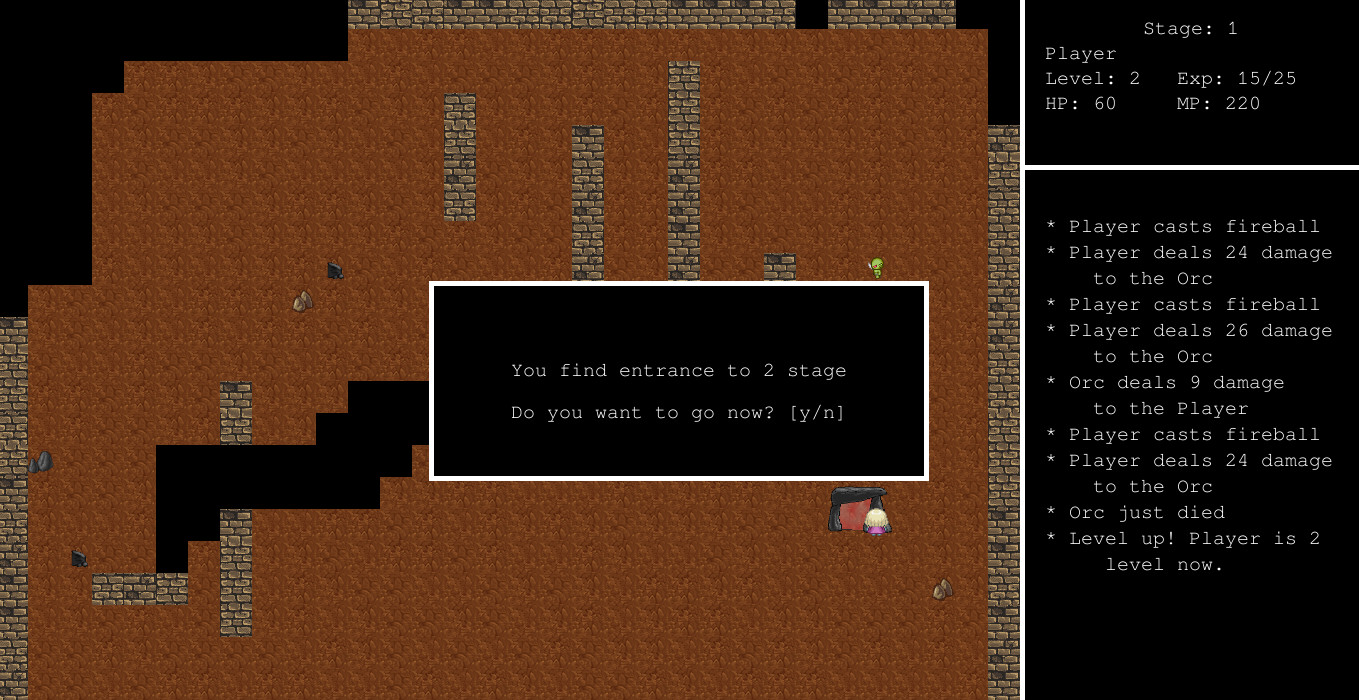


This is a game written in PHP using kphp-sdlite library.
Gameplay video: https://www.youtube.com/watch?v=L44l4Tqm4Fc
This game features:
- Audio processing (music, sound effects)
- Animations (spell effects)
- Text rendering and UI components
- Event polling (keyboard controls)
It’s a showcase that KPHP can be used to build applications like this.
Note that this game is written in 1 day during a hackathon. The code quality may be lacking.
Our build scripts expect a symlink to an appropriate kphp2cpp in the root of the project.
Example layout:
kphp-game/
kphp2cpp <- this is a symlink you need to provide
scripts/...
src/...
# If successfull, game binary can be found at ./bin/game
$ make gameTested on:
- Ubuntu (amd64 platform)
- Mac OS (amd64 platform)
$ make run-with-phpControls:
Q– use first spell, fireballW– use second spell, ice shardsE– use third spell, thunder- arrows (left, right, up, down) – move
Esc– exit gamey(when asked) – acceptn(when asked) – decline
- Tiles: https://opengameart.org/content/lots-of-free-2d-tiles-and-sprites-by-hyptosis (Hyptosis and Zabin)
- Units: https://pipoya.itch.io/pipoya-free-rpg-character-sprites-32×32 (Pipoya)
- Special effects: https://ppeldo.itch.io/2d-pixel-art-game-spellmagic-fx (Ppeldo)
- Background music: https://www.fesliyanstudios.com/royalty-free-music/download/land-of-fantasy/3
All assets keep their original copyright and can’t be considered to be MIT-licensed.
The authors of this game have no copyrights of these assets. The game (code from this repository) is provided as a demonstration and is not a commercial product.
 https://github.com/quasilyte/kphp-game
https://github.com/quasilyte/kphp-game